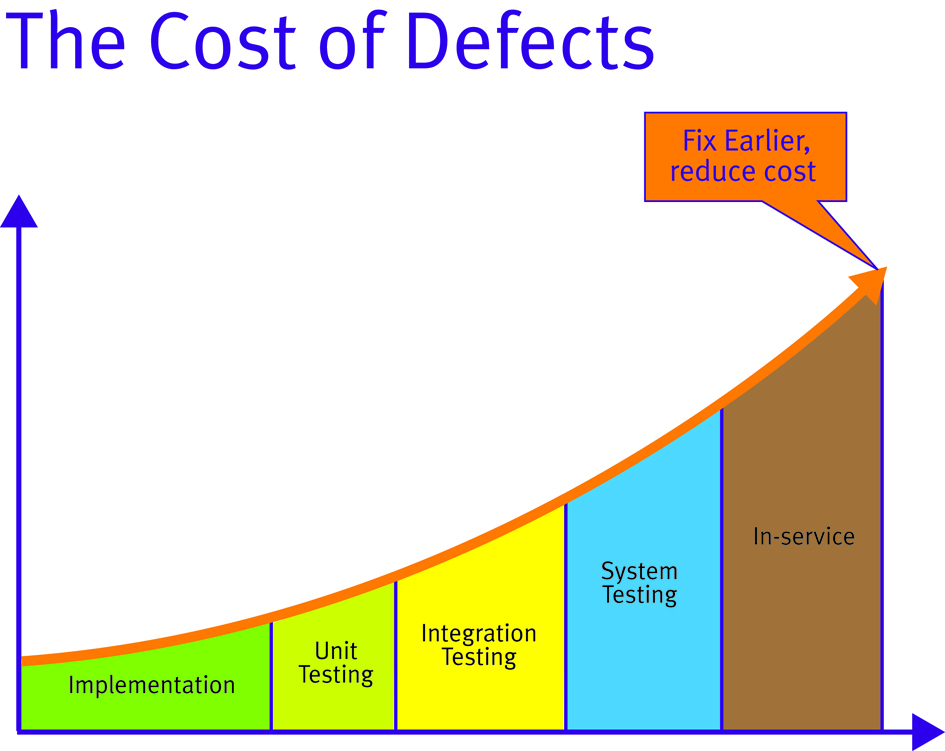
When are unit test tools justifiable? Ultimately, the justification of unit test tools comes down to a commercial decision. The later a defect is found in the product development, the more costly it is to fix (Figure 1). This is a concept first established in 1975 with the publication of Brooks’ “Mythical Man Month” and proven many times since through various studies.

The later a defect is identified, the higher the cost of rectifying it.
The automation of any process changes the dynamic of commercial justification. This is especially true of test tools given that they make earlier unit test more feasible. Consequently, modern unit test almost implies the use of such a tool unless only a handful of procedures are involved. Such unit test tools primarily serve to automatically generate the harness code which provides the main and associated calling functions or procedures (generically “procedures”). These facilitate compilation and allow unit testing to take place.
The tools not only provide the harness itself, but also statically analyze the source code to provide the details of each input and output parameter or global variable in any easily understood form. Where unit testing is performed on an isolated snippet of code, stubbing of called procedures can be an important aspect of unit testing. This can also be automated to further enhance the efficiency of the approach.
This automation makes the assignment of values to the procedure under test a simpler process, and one which demands little intimate knowledge of the code on the part of the test tool operator. This distance enables the necessary unit test objectivity because it divorces the test process from that of code development where circumstances require it, and from a pragmatic perspective, substantially lowers the level of skill required to develop unit tests.
This ease of use means that unit test can now be considered a viable development option with each procedure targeted as it is written. When these early unit tests identify weak code, the code can be corrected immediately while the original intent remains fresh in the mind of the developer.
Automatically generating test cases
Generally, the output data generated through unit tests is an important end in itself, but this is not necessarily always the case. There may be occasions when the fact that the unit tests have successfully completed is more important than the test data itself. This happens when source code is tested for robustness. To provide for such eventualities, it is possible to use test tools to automatically generate test data as well as the test cases. High levels of code execution coverage can be achieved by this means alone, and the resultant test cases can be complemented by means of manually generated test cases in the usual way.
An interesting application for this technology involves legacy code. Such code is often a valuable asset, proven in the field over many years, but likely developed on an experimental, ad hoc basis by a series of expert “gurus” – expert at getting things done and in the application itself, but not necessarily at complying with modern development practices.
Frequently this SOUP (software of unknown pedigree) forms the basis of new developments which are obliged to meet modern standards either due to client demands or because of a policy of continuous improvement within the developer organization. This situation may be further exacerbated by the fact that coding standards themselves are the subject of ongoing evolution, as the advent of MISRA C:2004 clearly demonstrates.
If there is a need to redevelop code to meet such standards, then this is a need to not only identify the aspects of the code which do not meet them, but also to ensure that in doing so the functionality of the software is not altered in unintended ways. The existing code may well be the soundest or only documentation available and so a means needs to be provided to ensure that it is dealt with as such.
Automatically generated test cases can be used to address just such an eventuality. By generating test cases using the legacy code and applying them to the rewritten version, it can be proven that the only changes in functionality are those deemed desirable at the outset.
The Apollo missions may have seemed irrelevant at the time, and yet hundreds of everyday products were developed or modified using aerospace research—from baby formula to swimsuits. Formula One racing is considered a rich man’s playground, and yet British soldiers benefit from the protective qualities of the light, strong materials first developed for racing cars. Hospital patients and premature babies stand a better chance of survival than they would have done a few years ago, thanks to the transfer of F1 know-how to the medical world.
Likewise, unit testing has long been perceived to be a worthy ideal—an exercise for those few involved with the development of high-integrity applications with budgets to match. But the advent of unit test tools offer mechanisms that optimize the development process for all. The availability of such tools has made this technology and unit testing itself an attractive proposition for applications where sound, reliable code is a commercial requirement, rather than only those applications with a life-and-death imperative.

{kind=link}